Repeaters
Repeaters allow to execute many times an HTTP request. There are scenarios where this is interesting:
- To obtain many different responses from the same endpoint.
- To download many files from a website.
- To make quality assurance, executing repetitions for each test case.
- To run load testing.
- Others.
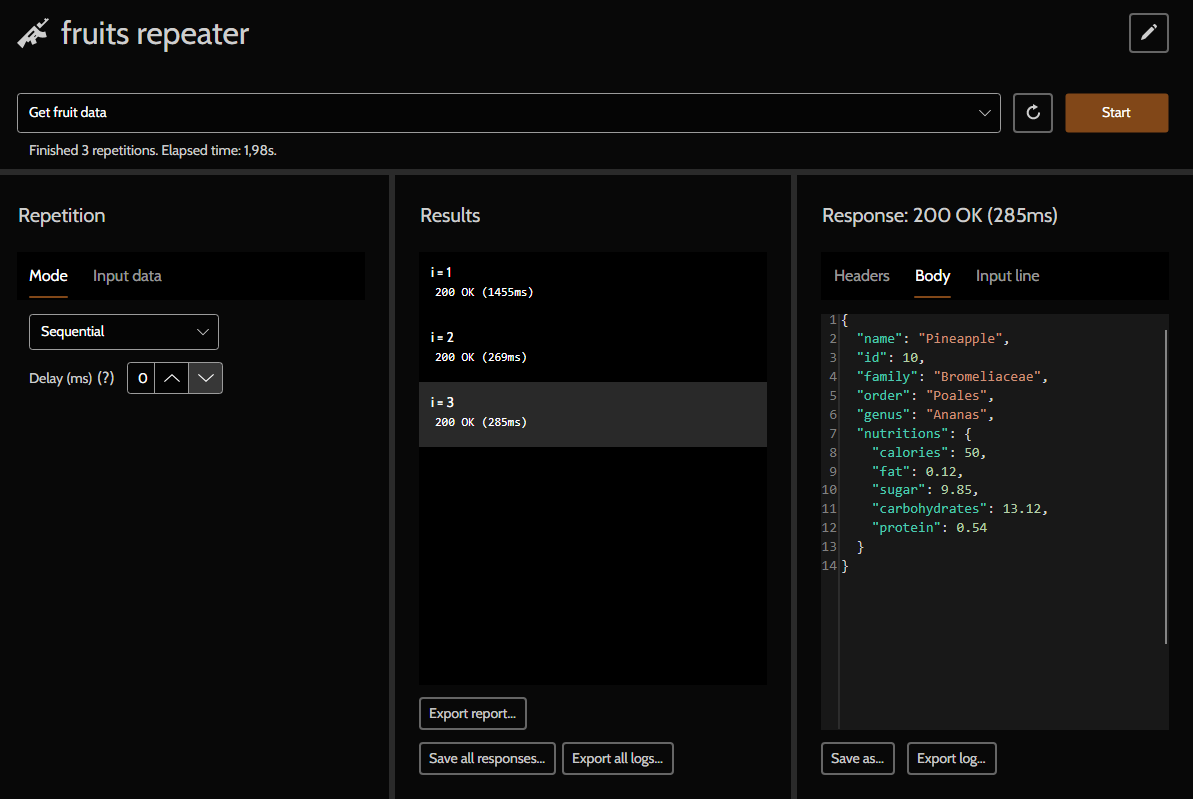
Repetition modes
Simple
In this type, the request is invariant, always the same for every execution.
Sequential
Sequential repetitions require input data (read more below), where each input line will correspond to a request. There is no parallelism in sequential mode: a request is sent only after the previous is finished, as in a queue.
Random
In random mode, each request shall use a random line from the input data. There is the possibility of redundance, that is, an input line be used in more than one successive request.
Parameters
Quantity is the number of requests that will be sent.
Parallelism determines the number of requests running at the same time.
Delay is the waiting time between the end of a request and the beginning of the next one.
Max reqs/s controls the maximum number of requests per second. It is different from parallelism.
INFO
In sequential mode, the quantity corresponds to the amount of input lines.
In case of parallelism, the delay happens independently in each parallel "track".
The value zero for max reqs/s means no limitation.
Input data
Input data provides values for requests variables, allowing variations among requests.
Suppose that you want to inquiry a Fruit API and get data about oranges, strawberries and pineapples. You can do that by creating a base HTTP request, GET https://www.fruityvice.com/api/fruit/{{fruitName}}, and then create a repeater, with the following input data:
[
{ "fruitName": "orange" },
{ "fruitName": "strawberry" },
{ "fruitName": "pineapple" },
]The input data format is a JSON array of objects, each object formed by string-string key-value pairs. Each object is considered an input line, each key-value pair is a variable (name-value).
[
// line 1
{
"variable1": "ABC",
"variable2": "123"
},
// line 2
{
"variable1": "DEF",
"variable2": "456"
},
// line 3
{
"variable1": "GHI",
"variable2": "789"
},
{
"variable1": "GHI",
"variable2": 789 // invalid: needs to be string-string
},
{
"variable1": "GHI",
"variable2": true // invalid: needs to be string-string
},
]TIP
In repeaters, input variables have precedence over collection and environment variables.
Load testing
Repeaters can be used for load testing, either by desktop or by dotnet test and console.
Pororoca, at least for now, doesn't measure latency or throughput.
INFO
HTTP/2 and HTTP/3 operate in a different way than HTTP/1, because they multiplex many calls into a single connection, while HTTP/1 spawns new TCP connections if there are no available idle connections in the pool; this is one of the reasons that these newer versions of HTTP are faster and more efficient.
This distinction implies that the parallelism with HTTP/2 and HTTP/3 works only up to a certain point, in that requests are enqueued internally before being sent through the connection. The maximum number of concurrent requests / stream in a single connection is server-side determined. There is an interesting issue on GitHub regarding this topic.
Automation and command-line
Read more in the Automated tests page.
Reports
At the end of the execution, you can extract a CSV report, containing info about result status (exception, cancelled, HTTP status code), started at, duration and which variables were used for that request.
Time plots on Excel
Let's make some plots.
Let's separate on a new column all single instants. For that, we will select the column startedAt, go to the tab Data, Sort & Filter, click on Advanced.
On the opened window, select Copy to another location. In Copy to, click and select the destination column. Also check Unique records only. Click on OK.
Change the column's header to instants.

Measure requests per second over time
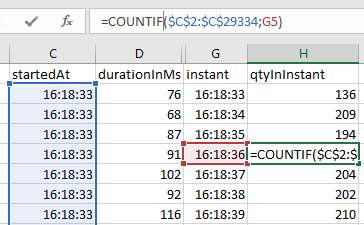
On a new column, let's add the header qtyInInstant.
On the cells of that column, we will use the formula
=COUNTIF($C$2:$C$10001;G2)to count how many times the instant (G2) repeats itself in the startedAt interval ($C$2:$C$10001). The dollar sign makes a rigid interval, that doesn't vary as the formula is copied to other cells.
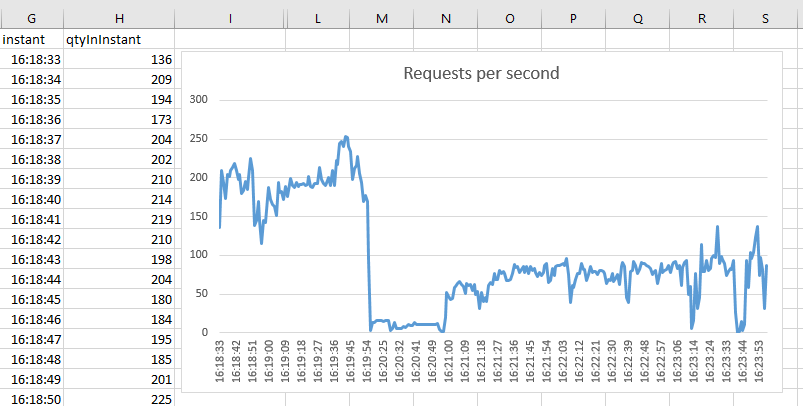
On the Insert tab, in the Charts group, click the Line symbol and create a chart. Right-click with the mouse on it and Select Data.
On Legend Entries (Series), let's pick the values for the Y-axis. Add, Series Values, then select all cells of the qtyInInstant column, except the header; it will be something like
='report_New HTTP repeater_Local_'!$H$2:$H$303. In Series Name, write Requests per second. OK.On Horizontal (Category) Axis Labels, let's pick the values for the X-axis. Edit and select all cells of the instant column, except the header; it will be something like
='report_New HTTP repeater_Local_'!$G$2:$G$303. OK and OK.
Measure successes and errors over time
The COUNTIFS function can be used, like: =COUNTIFS($C$2:$C$10001;G2;$B$2:$B$10001;"200 OK"):
- column C: startedAt
- column B: result
- column G: instant
"200 OK" filters for successes.
Average request duration over time
The AVERAGEIF function can be used, like: =AVERAGEIF($C$2:$C$10001;G2;$D$2:$D$10001):
- column C: startedAt
- column D: durationInMs
- column G: instant