Repetidoras
As repetidoras permitem executar várias vezes uma mesma requisição HTTP. Existem cenários em que isso é útil:
- Para obter respostas diversas de um mesmo endpoint.
- Para baixar vários arquivos de um site.
- Para garantia de qualidade, executando repetições para cada caso de teste.
- Para executar testes de carga.
- Entre outros.
Modos de repetição
Simples
Nesse tipo, a requisição é invariável, sempre a mesma para todas as execuções.
Seqüencial
As repetições seqüenciais requerem dados de entrada (leia mais a seguir), sendo que cada linha de entrada corresponderá a uma requisição. Não há paralelismo no modo seqüencial: uma requisição é enviada apenas após o fim da anterior, como em uma fila.
Aleatório
No modo aleatório, cada requisição utilizará uma linha de entrada aleatória escolhida dentre o conjunto fornecido. Pode haver redundância, isto é, uma linha de entrada ser usada em mais de uma requisição.
Parâmetros
A quantidade é o número de requisições que serão disparadas.
Paralelismo determina o número de requisições que rodam simultaneamente.
A espera é o tempo aguardado entre o fim de uma requisição e o início da próxima.
Máx. reqs/s controla o número máximo de requisições por segundo. É diferente de paralelismo.
INFO
No modo seqüencial, a quantidade de requisições corresponde ao número de linhas de entrada.
Em caso de paralelismo, a espera ocorre de forma independente em cada "pista" paralela.
Valor zero para máx. reqs/s significa que não há limitação.
Dados de entrada
Os dados de entrada fornecem valores para variáveis das requisições, permitindo variações entre as chamadas.
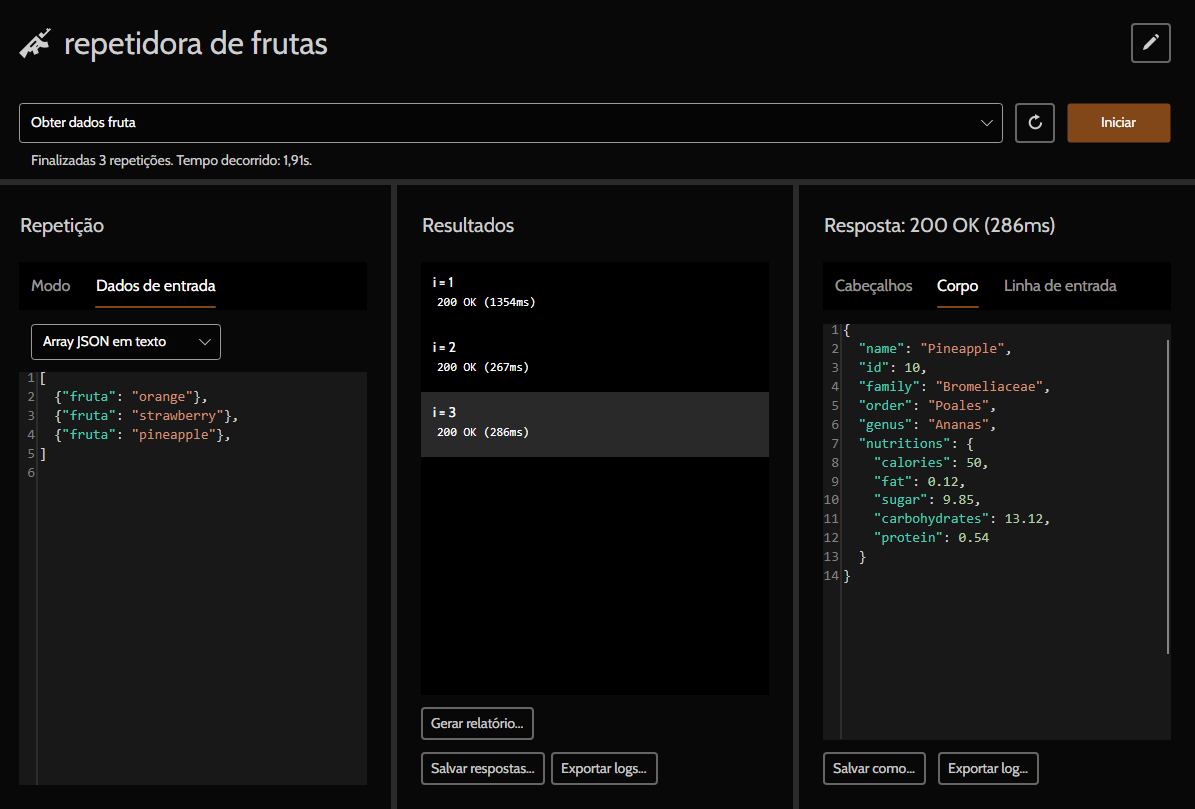
Suponha que você quer consultar uma API de frutas e obter dados sobre laranja (orange), morango (strawberry) e abacaxi (pineapple). Você pode fazer isso criando uma requisição HTTP base, GET https://www.fruityvice.com/api/fruit/{{fruta}}, e em seguida criar uma repetidora, com os seguintes dados de entrada:
[
{ "fruta": "orange" },
{ "fruta": "strawberry" },
{ "fruta": "pineapple" },
]O formato dos dados de entrada é um array JSON de objetos, cada objeto formado por pares chave-valor de string-string. Cada objeto é considerado uma linha de entrada e cada par chave-valor é uma variável (nome-valor).
[
// linha 1
{
"variavel1": "ABC",
"variavel2": "123"
},
// linha 2
{
"variavel1": "DEF",
"variavel2": "456"
},
// linha 3
{
"variavel1": "GHI",
"variavel2": "789"
},
{
"variavel1": "GHI",
"variavel2": 789 // inválido: precisa ser string-string
},
{
"variavel1": "GHI",
"variavel2": true // inválido: precisa ser string-string
},
]TIP
Em repetidoras, variáveis de entrada têm precedência sobre variáveis de coleção e de ambiente.
Testes de carga
As repetidoras podem ser usadas para testes de carga, através do desktop ou por dotnet test e console.
O Pororoca, pelo menos por enquanto, não mensura latência (ping) e banda (throughput).
INFO
HTTP/2 e HTTP/3 operam de forma diferente em relação ao HTTP/1, pois multiplexam várias chamadas em uma mesma conexão, enquanto que o HTTP/1 cria novas conexões TCP se não houver conexões ociosas disponíveis na pool; essa é uma das principais razões de as versões novas do HTTP serem mais eficientes e rápidas.
Essa distinção implica que o paralelismo com HTTP/2 e HTTP/3 funciona apenas até certo ponto, porque internamente as requisições entram em uma fila antes de serem enviadas através da conexão. O número máximo de requisições / streams concorrentes em uma mesma conexão é determinado do lado do servidor. Há uma issue interessante no GitHub sobre esse assunto.
Automação e linha de comando
Leia mais na página Testes automatizados.
Relatórios
Ao fim da execução, você pode extrair um relatório CSV das repetições, contendo informações sobre o status das respostas (exceção, cancelamento, HTTP status code), momento de início, duração e quais foram as variáveis usadas para aquela chamada.
Gráficos temporais no Excel
Vamos fazer alguns gráficos de exemplo.
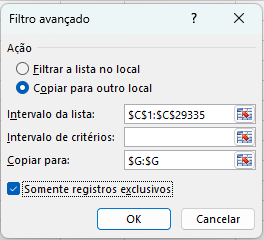
Vamos separar em uma nova coluna todos os instantes. Para isso, vamos selecionar a coluna startedAt, ir na aba Dados, em Classificar e Filtrar, clicar em Avançado.
Na janela aberta, escolher Copiar para outro local. Na caixa Copiar para, clicar e selecionar a coluna de destino na planilha. Após voltar à janela, marcar Somente registros exclusivos. Clicar em OK.
Vamos mudar o cabeçalho da coluna gerada para instante.
Medir requisições por segundo (vazão)
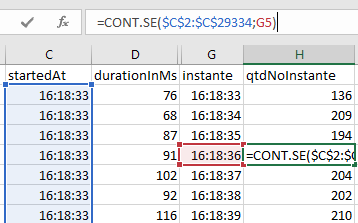
Em uma nova coluna, vamos colocar o cabeçalho qtdNoInstante.
Nas células dessa coluna usaremos a fórmula
=CONT.SE($C$2:$C$10001;G2)para contar quantas vezes o valor do instante (G2) se repete no intervalo ($C$2:$C$10001). O cifrão indica intervalo rígido, que não varia conforme a fórmula é copiada para outras células.
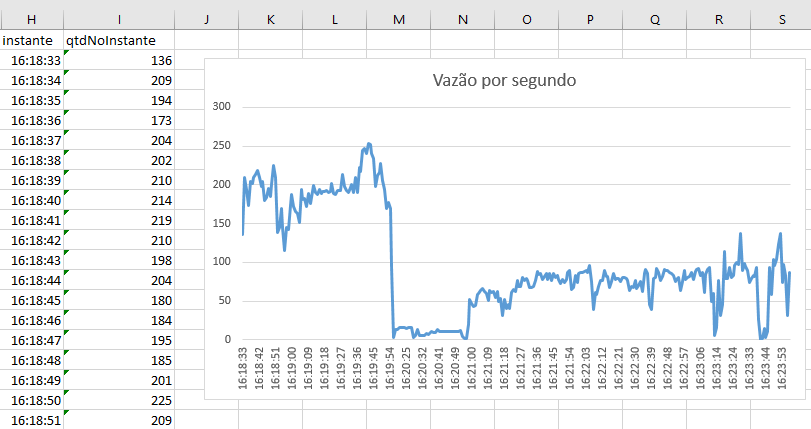
Vamos fazer um gráfico: Inserir, Gráfico de Linha. Clicar com o botão direito do mouse nele e Selecionar Dados.
Em Entradas de Legenda (Série), vamos escolher os valores do eixo Y. Clicar em Adicionar, depois em Valores da série, escolher todas as células da coluna qtdNoInstante, exceto o cabeçalho; vai ficar algo como
='report_New HTTP repeater_Local_'!$H$2:$H$303. Em Nome da série, escrever Vazão por segundo. Clicar em OK.Em Rótulos do Eixo Horizontal (Categorias), vamos escolher os valores do eixo X. Clicar em Editar e selecionar as células da coluna instante, exceto o cabeçalho; vai ficar algo como
='report_New HTTP repeater_Local_'!$G$2:$G$303. Clicar em OK e depois OK de novo.
Medir sucessos e erros por segundo
Usar a função CONT.SES, exemplo: =CONT.SES($C$2:$C$10001;G2;$B$2:$B$10001;"200 OK"):
- coluna C: startedAt
- coluna B: result
- coluna G: instante
"200 OK" é para filtrar por sucessos.
Duração média das requisições em cada instante
Usar a função MÉDIASE, exemplo: =MÉDIASE($C$2:$C$10001;G2;$D$2:$D$10001):
- coluna C: startedAt
- coluna D: durationInMs
- coluna G: instante